DATA POISONING
Data Poisoning of AI Initiatives: What is it and what to do about it
Data poisoning occurs when an attacker injects bad data into your model’s training data set. This approach tends to degrade the overall AI model leading to erroneous results.
By Gregory Richards

Data security is an important area of research that involves new methods of authentication (e.g., multi-factor authentication), secure sites (e.g., blockchains) and cybersecurity solutions (e.g., encryption).When it comes to AI however, less is known about potential attacks, but more research on data poisoning is emerging that is helping data scientists and managers improve security of their AI algorithms. It is an important issue because in some cases, such as autonomous vehicles, medical imaging, or precision medicine, these attacks can be downright dangerous.
This article reviews some of the recent research on the types of attacks being noted in the field and potential solutions which include ensuring proper data validation and cleaning, as is common in most AI projects, but the article also considers new ideas such as certified data sets and the use of cryptography for integrated management of the data pipeline.
Basics of Standard AI Algorithms
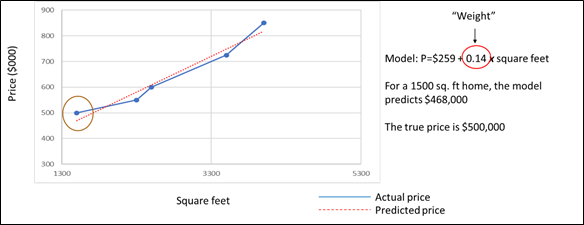
To understand how data poisoning works, we need to briefly review how an AI algorithm works. Neural networks are the most frequently-used approach for implementing AI. These networks can become extremely complex but fundamentally, the entire system is a predictive model (or a series of predictions in the case of deep learning). If, for example, we wanted to predict house prices (the response variable) based on square footage (the predictor variable), we’d need thousands or hundreds of thousands of examples of prices and square footage.
The figure below tells this story graphically. The blue line shows the actual relationship of actual and predicted data observed in our data set. But we want to predict house prices for square footage of houses that are not in our data set. To do this, we’d like to find a model that reduces prediction error (represented by the distance between the blue and the red lines in the graph above). This model’s equation is shown on the right in the figure. To create the equation, the data scientist would gather a large data set with thousands of examples of square footage and the associated house prices. The scientist will use some of the data to train the model, leading to identification of the intercept and weight that we will use for our prediction. The data scientist would then validate this model by using it to predict the prices of houses in the remainder of the data set. Here we are predicting a quantitative variable (the price of a house), but the same approach applies for classification engines such as image recognition (e.g., classifying animals as cats or dogs, or pictures of tumours as benign or malignant).
What is data poisoning?
Poisoning occurs when an attacker injects bad data into your model’s training data set. This approach tends to degrade the overall AI model leading to erroneous results.
How might this be done? Consider that nowadays, a lot of the data gathered for training AI algorithms are gathered through open sources: social media sites, published data for image recognition etc. Data poisoning can therefore occur if attackers access these sites and inject erroneous data. For training data within an organization, the attacker would need access to your training set, a situation that is less likely (but still possible if someone inside the organization has an axe to grind, or your system is externally hacked).
Adversarial attacks occur when the attacker inserts a new sample into the training set that pollutes the relationship between the predictor and the response variable. For image recognition classification systems, the output can sometimes be very far from the input as shown below when our kittens become misclassified as puppies.

Image Source: Francesco Gadaleta’s blog post
Another approach is referred to as backdoor poisoning attacks which tend to be more targeted and therefore more insidious. In the first case, where the training set might be compromised, the algorithm might converge poorly or not at all. In most instances, the data scientist can usually tell something is not right. In the second case, targeted attacks by contrast, can be difficult to detect. Research in the field of image recognition suggests that even exceedingly small changes can cause the system to misclassify the input variables.
Ilja Moisejevs’ “Towards Data Science” blog provides additional examples that includes logic corruption where the attacker changes the algorithm. This could result from someone inside the organization who has access to the system on which the AI algorithms are being developed. But, as AI tools become more widely deployed, we can expect that hackers will become more prevalent and more determined, therefore any hacks to the organization’s network might also compromise their AI implementations.
What to do about it?
Data cleaning is a key step in most data science projects. Here the defense is one of paying close attention to outliers or to algorithms that take a long time to produce results. In addition, it is important to ensure that if you are using external data to train algorithms, the data has been secured and cleaned before integration into the training set. The message here is that management of the overall data pipeline, from data definition and formatting, to capture through to implementation, must be a top priority for organizations applying AI, particularly if the tools are being used to automate decisions.
A new idea emerging from some researchers is the notion of a “fitchain”. The fitchain idea includes three core elements: certified training data sets, cryptographic proof of the data set and of the training model, and storage of the meta data and model in a blockchain-like public ledger. This approach aligns well with the concept of data pipeline management. In this case, critical components of the pipe include immutable ledger technology that alerts users to any changes to either data or to the algorithms during development of AI solutions. As AI becomes more popular, it’s no doubt that attempts to hack the algorithms will increase. An integrated data pipeline approach (not only for AI but for all types of analytics in the organization) would help keep managers abreast of the potential for harm, as well as steps they can take to avoid negative consequences.
About The Author

Gregory Richards, MBA, Ph.D., FCMC
Gregory is currently the Executive MBA Director and Adjunct Professor at the University of Ottawa. He was a visiting professor at the Western Management Development Centre in Denver, Colorado and a member of Peter Senge’s Society for Organizational Learning based at MIT. His research focuses on the use of analytics to generate usable organizational knowledge.
