FEATURES
Five Keys towards Responsible Analytics
By Gregory Richards

The emphasis on responsible artificial intelligence (AI) recognizes that these algorithms can help with decision-making as well as streamlining certain types of business processes. But because the algorithmic outputs are driven by current data, any bias that exists in the data will also exist in the output. You must have heard of hiring engines that tend to recommend males more than females because the data used accurately reflected the fact that there were more males currently working in certain positions than females. Managers, therefore, should be especially vigilant when seeking to automate or semi-automate decisions.
But the problem of “responsibility” is broader than AI—it applies to all analytics being used in organizations. In this paper, I address the broader question of responsible analytics arguing that AI is one analytic tool among many that can be deployed in organizations and that since all forms of analytics use data, managers need to build practices that include responsible analytics.
A key point related to this issue is that many organizations are creating data strategies, but few develop analytic strategies. While the data strategy focuses on sound data management including privacy and confidentiality, an analytics strategy would focus on how data are used in the organization to improve effectiveness. Ensuring responsible use should be part of this strategy.
Generally speaking, four components should be integrated into an analytics strategy: visualizations, association modelling, efficiency modelling and what-if scenario planning. Each of these components calls for the use of data in mathematical formulae that lend themselves to manipulation if we don’t exercise proper care. This point was made eloquently in Darrell Huff’s 993 book “How to Lie with Statistics”. The issues Huff pointed out are as relevant today as they were in 1993. But the implications are broader given the growing emphasis on analytics in modern day organizations.
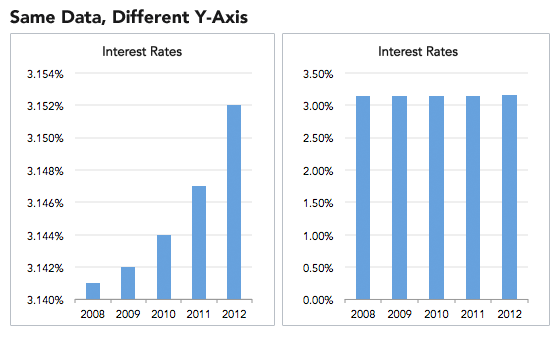
Here is an example of a visualization from datapine.com showing how easy it is to mislead with visualizations unless the reader is careful to check the scale on the y-axis. The charts fall into the visualization component discussed above. When the graphs are compared side-to-side, it is easy to see that the graph on the left, without a 0 origin, can easily mislead if someone is reading quickly.
It’s a simple example, but the point is that data, in general, are used to make decisions. Unless organizations practice responsible analytics, these decisions will lead to some people being disenfranchised depending on the context and the types of decisions being made.
How should managers avoid these problems? One approach is to publish guidelines for visualizations that include proper labeling, consistent axes, and required annotations. In other words, being responsible for the use of analytics means creating frameworks for each component in your analytics strategy.
As another example, consider that AI is a sophisticated form in a family of association modeling techniques. One such technique commonly used in organizations is regression modeling, which helps us understand how one thing is related to another. For example, if we want to deliver better services to citizens, a regression model might generate a regression coefficient that tells us that for each new staff person added, service speed will increase by 15 minutes. We use this relationship to plan our investment in staffing.
Regression models depend on the sampling of data from a larger population, and several critical assumptions about the distribution of the data need to be met if we are to have confidence in the output of the model. If these assumptions are violated, we might end up hiring too many or too few staff to meet the demand for services. We exceed our budget on the one hand or drive dissatisfaction on the other. Guidelines, therefore, for checking regression model assumptions should be in place before managers begin to apply these techniques.
In the broader domain of machine learning and AI, an organization’s data strategy will often address data quality: accuracy, timeliness, and availability of data for example. But, as mentioned earlier, it is possible to use data that accurately represent reality but that leads to biased outcomes. We should be aware that AI algorithms are based on common mathematical optimization techniques that look for relationships among two or more variables. The algorithm then uses this relationship to predict an outcome. For example, if I’m interested in predicting when someone is likely to retire (what I’ll call the “outcome” for sake of discussion), I might gather information on age, salary, number of children, etc., on a large number of people. Some of these we know will have retired and some will still be working. I’d then split the data in two to create a “training” set that identifies the regression coefficients and a “test” set that I use to test these coefficients for accuracy. The result is an association model with coefficients (or weights) for some combination of age, salary and number of children that predict who is likely to retire on a new data set where I don’t already know the outcome.
The important point is that using a different data set to train the algorithm (i.e., to identify the regression coefficients that predict outcomes we care about) will generate a different association model. Therefore, guidelines about how data are selected, treated and tested along with standards for data accuracy and model validation should be a key feature of analytics use in organizations.
Responsible analytics then, is not just about the protection of data, it’s about protection of the rigour and validity of the decisions managers will make using any form of analytic tool. For responsible analytics to prevail, whether in an AI algorithm or some other model, managers need to create the following five conditions: Data sets are representative of the groups for which they will be used. Data sets are as complete as possible and outliers are managed. Data Scientists understand the business problem enough to be able to identify which data sets might not be appropriate. Everyone, Data Scientists and managers, knows enough about responsible analytics to carefully check assumptions before using any form of analytics for important decisions. Guidelines for all components in an organization’s analytics strategy are published to ensure appropriate use and deployment of analytic tools and techniques.
